Introduction
In the following series of articles, I want to explore the use of streaming engines for network analyses. For that end, I decided to use Kafka Streams for its simplicity. It doesn't require the setup of clusters, complex configurations,...It is a matter of including kafka streaming jar dependency in your application and you are ready to go. When load increases just spawn another instance of your application.
Where this small toy project will lead me is unknown.
Note that, there are already some heavy weight projects such as Metron which use streaming engines which enables us to similar analyses. Other projects of the same kind, not using streaming platforms, are Bro , YAF or Moloch.
Traditionally, protocol state handling and packet reassembly are performed by monolithic blocks of code written usually in "C/C++", sometimes in Go. We find it for example in Operating Systems, or applications such as Wireshark, Tcpdump, or PacketBeat
After that initial packet capture and parsing is done, a packet summary is forwarded to some framework for indexing, analysis,...
One of the drawbacks of sending only packet summaries, is that low level analyses is not possible anymore further down the line.
Below a diagram of the setup I am going to experiment with.
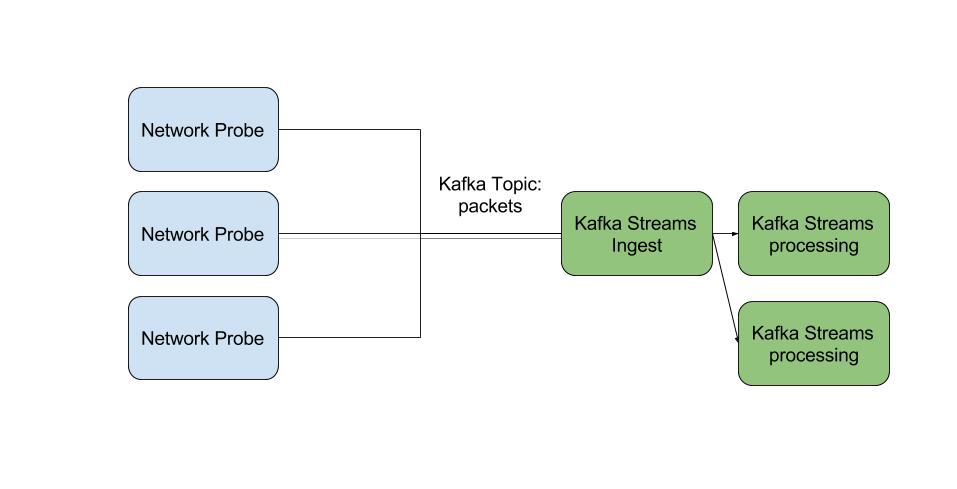 |
| Setup |
The Network probe
The network probe implemented is very simple. It is written in C++/C and uses the standard pcap library for packet capture and librdkafka for transmitting record on Kafka for further processing.
The probe itself is single threaded. The librdkafka, however, uses multiple threads internally.
We use the standard network 5 Tuple: source & destination IP address, protocol, source & destination port as the Kafka key for the configured topic. By using the network 5 Tuple as key, we guarantee that packets belonging to the same stream are handled by the same Kafka consumers down the line.
We need also to arrange the 5 tuple is such a way that both directions of the same stream have the same key.
In this toy network probe, only basic Ethernet II packet parsing was implemented, no 802.1q vlans, and others were implemented.
Modern cards Ethernet cards offload the CPU by automatically reassembling TCP segments. Artificial large packets are received by the network driver and all layers above.
In order to capture the TCP/UDP packets as they are received by the network card, you need to disable the network cards generic receive offload if present at all (sometimes also LRO, TRO,...)
On Linux you can do that with
sudo ethtool ethX -K gro off
For high performance SW based probes, frameworks such as DPDK, PF_RING, NETMAP are recommended.
The probe itself is single threaded. The librdkafka, however, uses multiple threads internally.
We use the standard network 5 Tuple: source & destination IP address, protocol, source & destination port as the Kafka key for the configured topic. By using the network 5 Tuple as key, we guarantee that packets belonging to the same stream are handled by the same Kafka consumers down the line.
We need also to arrange the 5 tuple is such a way that both directions of the same stream have the same key.
In this toy network probe, only basic Ethernet II packet parsing was implemented, no 802.1q vlans, and others were implemented.
Modern cards Ethernet cards offload the CPU by automatically reassembling TCP segments. Artificial large packets are received by the network driver and all layers above.
In order to capture the TCP/UDP packets as they are received by the network card, you need to disable the network cards generic receive offload if present at all (sometimes also LRO, TRO,...)
On Linux you can do that with
sudo ethtool ethX -K gro off
For high performance SW based probes, frameworks such as DPDK, PF_RING, NETMAP are recommended.
Streaming part
In this article, I decided to use Kafka Streams but any other Streaming platform would have been equally valid.The first step is to ingest the Kafka records produced by the network probes discussed here above.
The binary encoded Kafka Key/Value records produced by the network probes, are deserialized to Net5Tuple POJO's as the key and a ByteArray for the value.
1 | final KStream<Net5Tuple, byte []> packetStream = builder.stream(net5TupleSerde, byteArraySerde, "packets"); |
We configure the default Serializers/Deserializers as follows:
1 2 | streamsConfiguration.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, net5TupleSerde.getClass().getName()); streamsConfiguration.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.ByteArray().getClass().getName()); |
The Net5Tuple class uses NIO's ByteBuffers to map the binary fields into their Java counterparts. NIO uses by default Big Endian(network order) ordering, which is the ordering used to encode IP addresses and ports.
From that point on, we can start using Streaming primitives to perform packet reassembly and decoding, collect statistics and perform analyses.
Examples
I will show here 2 small examples of what can be done. More complex examples such as TCP packet reassembly, http decoding will be handled in future articles.
Packet statistics
Here we print on the console packet statistics per stream. Note: this bare meaning only in the case of TCP and UDP.
1 2 3 4 5 | packetStream.groupByKey(net5TupleSerde, byteArraySerde) .count() .toStream() .map((k,v) -> KeyValue.pair(k.toString(), v)) .print(); |
We could use here also a KTable and then access externally the statistics via REST API's
SubStreams according to protocol
1 2 3 4 5 | KStream<Net5Tuple, byte []> [] perProtoStream = packetStream.branch( (k,v) -> k.getProtocol() == TCP, (k,v) -> k.getProtocol() == UDP, (k,v) -> true ); |
References:
- Kafka: a distributed streaming platform
- Kafka Streams: streaming engine on top of the Kafka
- LibPcap: packet capture library
- Code for the network probe is available upon request.
- DPDK: user mode data plane libraries


